 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Theorize the World from Observation
May 05, 2026What does it mean to understand the world? Contemporary world models often operationalize understanding as accurate future prediction in latent or observation space. Developmental cognitive science, however, suggests a different view: human understanding emerges through the construction of internal theories of how the world works, even before mature language is acquired. Inspired by this theory-building view of cognition, we introduce Learning-to-Theorize, a learning paradigm for inferring explicit explanatory theories of the world from raw, non-textual observations. We instantiate this paradigm with the Neural Theorizer (NEO), a probabilistic neural model that induces latent programs as a learned Language of Thought and executes them through a shared transition model. In NEO, a theory is represented as an executable, compositional program whose learned primitives can be systematically recombined to explain novel phenomena. Experiments show that this formulation enables explanation-driven generalization, allowing observations to be understood in terms of the programs that generate them.
Tipiano: Cascaded Piano Hand Motion Synthesis via Fingertip Priors
Apr 06, 2026Synthesizing realistic piano hand motions requires both precision and naturalness. Physics-based methods achieve precision but produce stiff motions; data-driven models learn natural dynamics but struggle with positional accuracy. Piano motion exhibits a natural hierarchy: fingertip positions are nearly deterministic given piano geometry and fingering, while wrist and intermediate joints offer stylistic freedom. We present [OURS], a four-stage framework exploiting this hierarchy: (1) statistics-based fingertip positioning, (2) FiLM-conditioned trajectory refinement, (3) wrist estimation, and (4) STGCN-based pose synthesis. We contribute expert-annotated fingerings for the FürElise dataset (153 pieces, ~10 hours). Experiments demonstrate F1 = 0.910, substantially outperforming diffusion baselines (F1 = 0.121), with user study (N=41) confirming quality approaching motion capture. Expert evaluation by professional pianists (N=5) identified anticipatory motion as the key remaining gap, providing concrete directions for future improvement.
Adaptive Cyclic Diffusion for Inference Scaling
May 20, 2025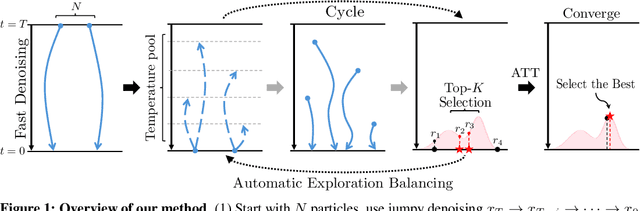

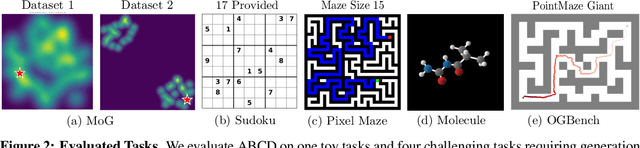
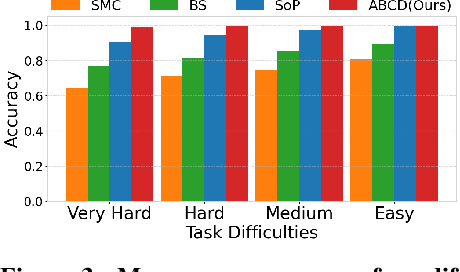
Diffusion models have demonstrated strong generative capabilities across domains ranging from image synthesis to complex reasoning tasks. However, most inference-time scaling methods rely on fixed denoising schedules, limiting their ability to allocate computation based on instance difficulty or task-specific demands adaptively. We introduce the challenge of adaptive inference-time scaling-dynamically adjusting computational effort during inference-and propose Adaptive Bi-directional Cyclic Diffusion (ABCD), a flexible, search-based inference framework. ABCD refines outputs through bi-directional diffusion cycles while adaptively controlling exploration depth and termination. It comprises three components: Cyclic Diffusion Search, Automatic Exploration-Exploitation Balancing, and Adaptive Thinking Time. Experiments show that ABCD improves performance across diverse tasks while maintaining computational efficiency.
CONMOD: Controllable Neural Frame-based Modulation Effects
Jun 20, 2024



Deep learning models have seen widespread use in modelling LFO-driven audio effects, such as phaser and flanger. Although existing neural architectures exhibit high-quality emulation of individual effects, they do not possess the capability to manipulate the output via control parameters. To address this issue, we introduce Controllable Neural Frame-based Modulation Effects (CONMOD), a single black-box model which emulates various LFO-driven effects in a frame-wise manner, offering control over LFO frequency and feedback parameters. Additionally, the model is capable of learning the continuous embedding space of two distinct phaser effects, enabling us to steer between effects and achieve creative outputs. Our model outperforms previous work while possessing both controllability and universality, presenting opportunities to enhance creativity in modern LFO-driven audio effects.